A nontrivial problem with machine learning is organization of new information and recollection of appropriate information in a given circumstance. Simple storing of information (cats are furry, balls bounce, water is wet) is relatively straightforward, and one common approach to doing this is simply to define the individual pieces of knowledge as objects which contain things (water, cats, balls) and descriptors (water is wet, water flows, water is necessary for life; cats are furry, cats meow, cats are egocentric little psychopaths).
This presents a problem with information storage and retrieval. Some information systems that have a specific function, such as expert systems that diagnose illness or identify animals, solve this problem by representing the information hierarchically as a tree, with the individual units of information at the tree’s branches and a series of questions representing paths through the tree. For instance, if an expert system identifies an animal, it might start with the question “is this animal a mammal?” A “yes” starts down one side of the tree, and a “no” starts down the other. At each node in the tree, another question identifies which branch to take—”Is the animal four-legged?” “Does the animal eat meat?” “Does the animal have hooves?” Each path through the tree is a series of questions that leads ultimately to a single leaf.
This is one of the earliest approaches to expert systems, and it’s quite successful for representing hierarchical knowledge and for performing certain tasks like identifying animals. Some of these expert systems are superior to humans at the same tasks. But the domain of cognitive tasks that can be represented by this variety of expert system is limited. Organic brains do not really seem to organize knowledge this way.
Instead, we can think of the organization of information in an organic brain as a series of individual facts that are context dependent. In this view, a “context” represents a particular domain of knowledge—how to build a model, say, or change a diaper. There may be thousands, tens of thousands, or millions of contexts a person can move within, and a particular piece of information might belong to many contexts.
What is a context?
A context might be thought of as a set of pieces of information organized into a domain in which those pieces of information are relevant to each other. Contexts may be procedural (the set of pieces of information organized into necessary steps for baking a loaf of bread), taxonomic (a set of related pieces of information arranged into a hierarchy, such as knowledge of the various birds of North America), hierarchical (the set of information necessary for diagnosing an illness), or simply related to one another experientially (the set of information we associate with “visiting grandmother at the beach).
Contexts overlap and have fuzzy boundaries. In organic brains, even hierarchical or procedural contexts will have extensive overlap with experiential contexts—the context of “how to bake bread” will overlap with the smell of baking bread, our memories of the time we learned to bake bread, and so on. It’s probably very, very rare in an organic brain that any particular piece of information belongs to only one context.
In a machine, we might represent this by creating a structure of contexts CX (1,2,3,4,5,…n) where each piece of information is tagged with the contexts it belongs to. For instance, “water” might appear in many contexts: a context called “boating,” a context called “drinking,” a context called “wet,” a context called “transparent,” a context called “things that can kill me,” a context called “going to the beach,” and a context called “diving.” In each of these contexts, “water” may be assigned different attributes, whose relevance is assigned different weights based on the context. “Water might cause me to drown” has a low relevance in the context of “drinking” or “making bread,” and a high relevance in the context of “swimming.”
In a contextually based information storage system, new knowledge is gained by taking new information and assigning it correctly to relevant contexts, or creating new contexts. Contexts themselves may be arranged as expert systems or not, depending on the nature of the context. A human doctor diagnosing illness might have, for instance, a diagnostic context that behaves similarly in some ways to the way a diagnostic expert system; a doctor might ask a patient questions about his symptoms, and arrive at her conclusion by following the answers to a single possible diagnosis. This process might be informed by past contexts, though; if she has just seen a dozen patients with norovirus, her knowledge of those past diagnoses, her understanding of how contagious norovirus is, and her observation of the similarity of this new patient’s symptoms to those previous patients’ symptoms might allow her to bypass a large part of the decision tree. Indeed, it is possible that a great deal of what we call “intuition” is actually the ability to make observations and use heuristics that allow us to bypass parts of an expert system tree and arrive at a leaf very quickly.
But not all types of cognitive tasks can be represented as traditional expert systems. Tasks that require things like creativity, for example, might not be well represented by highly static decision trees.
When we navigate the world around us, we’re called on to perform large numbers of cognitive tasks seamlessly and to be able to switch between them effortlessly. A large part of this process might be thought of as context switching. A context represents a domain of knowledge and information—how to drive a car or prepare a meal—and organic brains show a remarkable flexibility in changing contexts. Even in the course of a conversation over a dinner table, we might change contexts dozens of times.
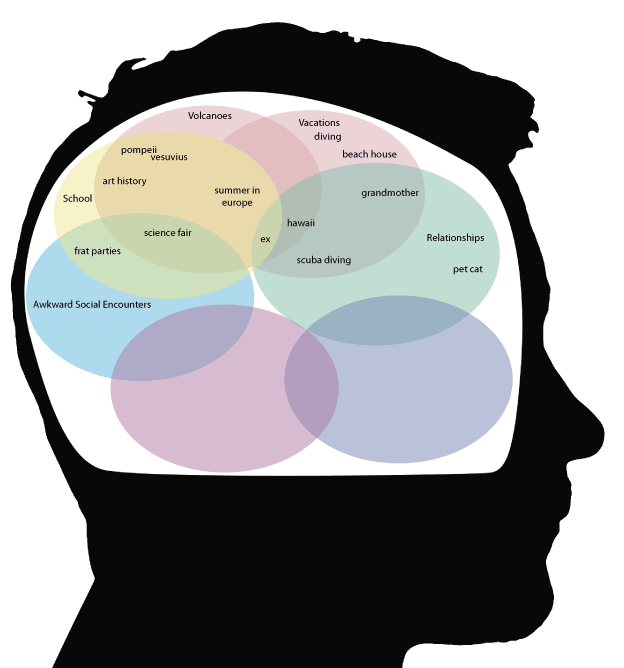
A flexible machine learning system needs to be able to switch contexts easily as well, and deal with context changes resiliently. Consider a dinner conversation that moves from art history to the destruction of Pompeii to a vacation that involved climbing mountains in Hawaii to a grandparent who lived on the beach. Each of these represents a different context, but the changes between contexts aren’t arbitrary. If we follow the normal course of conversations, there are usually trains of thought that lead from one subject to the next; and these trains of thought might be represented as information stored in multiple contexts. Art history and Pompeii are two contexts that share specific pieces of information (famous paintings) in common. Pompeii and Hawaii are contexts that share volcanoes in common. Understanding the organization of individual pieces of information into different contexts is vital to understanding the shifts in an ordinary human conversation; where we lack information—for example, if we don’t know that Pompeii was destroyed by a volcano—the conversation appears arbitrary and unconnected.
There is a danger in a system being too prone to context shifts; it meanders endlessly, unable to stay on a particular cognitive task. A system that changes contexts only with difficulty, on the other hand, appears rigid, even stubborn. We might represent focus, then, in terms of how strongly (or not) we cling to whatever context we’re in. Dustin Hoffman’s character in Rain Man possesses a cognitive system that clung very tightly to the context he was in!
Other properties of organic brains and human knowledge might also be represented in terms of information organized into contexts. Creativity is the ability to find connections between pieces of information that normally exist in different contexts, and to find commonalities of contextual overlap between them. Perception is the ability to assign new information to relevant contexts easily.
Representing contexts in a machine learning system is a nontrivial challenge. It is difficult, to begin with, to determine how many contexts might exist. As a machine entity gains new information and learns to perform new cognitive tasks, the number of contexts in which it can operate might increase indefinitely, and the system must be able to assign old information to new contexts as it encounters them. If we think of each new task we might want the machine learning system to be able to perform as a context, we need to devise mechanisms by which old information can be assigned to these new contexts.
Organic brains, of course, don’t represent information the way computers do. Organic brains represent information as neural traces—specific activation pathways among collections of neurons.
These pathways become biased toward activation when we are in situations similar to those where they were first formed, or similar to situations in which they have been previously activated. For example, when we talk about Pompeii, if we’re aware that it was destroyed by a volcano, other pathways pertaining to our experiences with or understanding of volcanoes become biased toward activation—and so, for example, our vacation climbing the volcanoes in Hawaii come to mind. When others share these same pieces of information, their pathways similarly become biased toward activation, and so they can follow the transition from talking about Pompeii to talking about Hawaii.
This method of encoding and recalling information makes organic brains very good at tasks like pattern recognition and associating new information with old information. In the process of recalling memories or performing tasks, we also rewrite those memories, so the process of assigning old information to new contexts is transparent and seamless. (A downside of this approach is information reliability; the more often we access a particular memory, the more often we rewrite it, so paradoxically, the memories we recall most often tend to be the least reliable.)
Machine learning systems need a system for tagging individual units of information with contexts. This becomes complex from an implementation perspective when we recall that simply storing a bit of information with descriptors (such as water is wet, water is necessary for life, and so on) is not sufficient; each of those descriptors has a value that changes depending on context. Representing contexts as a simple array CX (1,2,3,4,…n) and assigning individual facts to contexts (water belongs to contexts 2, 17, 43, 156, 287, and 344) is not sufficient. The properties associated with water will have different weights—different relevancies—depending on the context.
Machine learning systems also need a mechanism for recognizing contexts (it would not do for a general purpose machine learning system to respond to a fire alarm by beginning to bake bread) and for following changes in context without becoming confused. Additionally, contexts themselves are hierarchical; if a person is driving a car, that cognitive task will tend to override other cognitive tasks, like preparing notes for a lecture. Attempting to switch contexts in the middle of driving can be problematic. Some contexts, therefore, are more “sticky” than others, more resistant to switching out of.
A context-based machine learning system, then, must be able to recognize context and prioritize contexts. Context recognition is itself a nontrivial problem, based on recognition of input the system is provided with, assignment of that input to contexts, and seeking the most relevant context (which may in most situations be the context with greatest overlap with all the relevant input). Assigning some cognitive tasks, such as diagnosing an illness, to a context is easy; assigning other tasks, such as natural language recognition, processing, and generation in a conversation, to a context is more difficult to do. (We can view engaging in natural conversation as one context, with the topics of the conversation belonging to sub-contexts. This is a different approach than that taken by many machine conversational approaches, such as Markov chains, which can be viewed as memoryless state machines. Each state, which may correspond for example to a word being generated in a sentence, can be represented by S(n), and the transition from S(n) to S(n+1) is completely independent of S(n-1); previous parts of the conversation are not relevant to future parts. This creates limitations, as human conversations do not progress this way; previous parts of a conversation may influence future parts.)
Context seems to be an important part of flexibility in cognitive tasks, and thinking of information in terms not just of object/descriptor or decision trees but also in terms of context may be an important part of the next generation of machine learning systems.
This a great review of the main issues, really appreciated. It deserves – perhaps following a bit of tightening up here and there – some circulation.
I wonder if the introduction of contextual prioritisation may not result in race conditions? And if the system does allow for multiple prioritisation does this not lead to the possibility of distorted thinking (e.g., the task is to feed the cat, but the effectiveness in interrupted, because the cat reminds the thinker about a flawed relationship with their ex and a process starts on how to avoid that situation in the future, and the cat food ends on the floor…)
and for performing certain tasks like identifying animals.
A little off-topic (out-of-context?) I had a chuckle at this because it reminds me of the opening pages of the Sandy Petersen Guide to the Monsters of the Cthulhu mythos where the decision tree has wonderful questions such as “Is it invisible?”, “Does it have a head?” etc.
Contextualuzation in organic brains sometimes leads to race conditions. I’ve had the experience of going to change the cat’s litter, realizing I need to take out the trash, which reminded me I needed to clean a bunch of stuff out of the closet, which made me remember the closet door needs to be fixed…and the next thing I know I’m searching for a screwdriver and the cat’s all “but what about me?”
An expert system decision tree for identifying creatures in the Cthulhu mythos sounds EPIC!
Cat’s are always “but what about me?” 🙂
The expert system decision trees are available in
Sandy Petersen’s Field Guide to Cthulhu Monsters &
Sandy Petersen’s Field Guide to Creatures of the Dreamlands
Apart from the decision tree (which really, I should just spend an hour and write up the code), there’s also a relative sizes chart. Most of the two books is a page of description of a particular Lovecraftian horror and a full-page, full-colour illustration. They’re pretty nice pieces.
If I recall correctly at least one of them won an Origins Award in the late 80s
This a great review of the main issues, really appreciated. It deserves – perhaps following a bit of tightening up here and there – some circulation.
I wonder if the introduction of contextual prioritisation may not result in race conditions? And if the system does allow for multiple prioritisation does this not lead to the possibility of distorted thinking (e.g., the task is to feed the cat, but the effectiveness in interrupted, because the cat reminds the thinker about a flawed relationship with their ex and a process starts on how to avoid that situation in the future, and the cat food ends on the floor…)
and for performing certain tasks like identifying animals.
A little off-topic (out-of-context?) I had a chuckle at this because it reminds me of the opening pages of the Sandy Petersen Guide to the Monsters of the Cthulhu mythos where the decision tree has wonderful questions such as “Is it invisible?”, “Does it have a head?” etc.
Contextualuzation in organic brains sometimes leads to race conditions. I’ve had the experience of going to change the cat’s litter, realizing I need to take out the trash, which reminded me I needed to clean a bunch of stuff out of the closet, which made me remember the closet door needs to be fixed…and the next thing I know I’m searching for a screwdriver and the cat’s all “but what about me?”
An expert system decision tree for identifying creatures in the Cthulhu mythos sounds EPIC!
Cat’s are always “but what about me?” 🙂
The expert system decision trees are available in
Sandy Petersen’s Field Guide to Cthulhu Monsters &
Sandy Petersen’s Field Guide to Creatures of the Dreamlands
Apart from the decision tree (which really, I should just spend an hour and write up the code), there’s also a relative sizes chart. Most of the two books is a page of description of a particular Lovecraftian horror and a full-page, full-colour illustration. They’re pretty nice pieces.
If I recall correctly at least one of them won an Origins Award in the late 80s
It seems like the old LJ style-sheet of making the tags you use the most bigger, surrounded by and progressively smaller (font size) words is a good model.
The other problem I see with this is…it’s too simplistic, single-threaded. Tags, again, seem to be a better…mind-model than contexts?
We think of volcanos, which makes us think of that girl we climbed the volcano with, which reminds us of…poi and we have a craving, or a conversation about it. All those tags go with ‘her’ and ‘volcanos’. The other neat thing that occurred to me is…intuition could be simulated in a machine, by letting it pattern-recognize tasks. Like…’oh baking bread is similar to doing surgery in this way/mechanism/work-flow pathway’ Which…computers might actually be amazing at seeing solutions and unique things like that, that the average person doesn’t realize is (in some way) ‘the same’.
K.
It seems like the old LJ style-sheet of making the tags you use the most bigger, surrounded by and progressively smaller (font size) words is a good model.
The other problem I see with this is…it’s too simplistic, single-threaded. Tags, again, seem to be a better…mind-model than contexts?
We think of volcanos, which makes us think of that girl we climbed the volcano with, which reminds us of…poi and we have a craving, or a conversation about it. All those tags go with ‘her’ and ‘volcanos’. The other neat thing that occurred to me is…intuition could be simulated in a machine, by letting it pattern-recognize tasks. Like…’oh baking bread is similar to doing surgery in this way/mechanism/work-flow pathway’ Which…computers might actually be amazing at seeing solutions and unique things like that, that the average person doesn’t realize is (in some way) ‘the same’.
K.